Hadoop Cluster
In Terrascope, we harness the power of Hadoop, Spark, and YARN to manage and process our extensive Earth observation data efficiently. Our platform leverages these technologies to ensure robust data handling, fast processing, and optimal resource management.
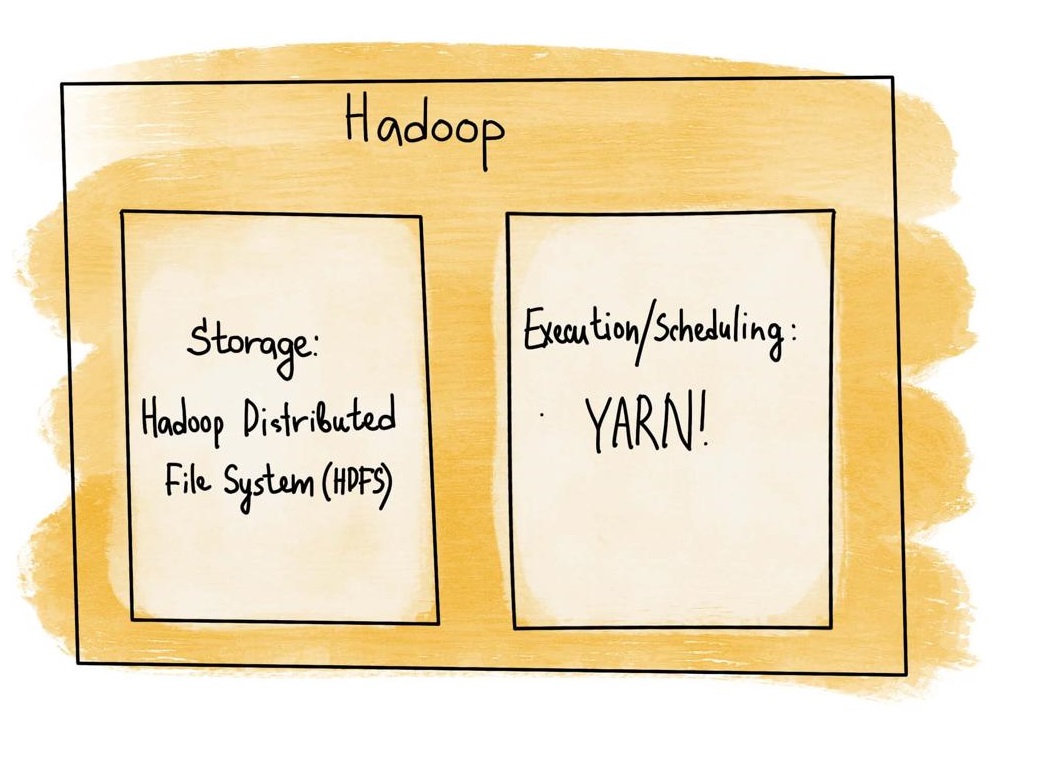
Hadoop
At the core of our data storage system is Hadoop’s HDFS (Hadoop Distributed File System). It enables us to distribute vast amounts of satellite imagery across multiple nodes, ensuring reliability and accessibility.
Spark
Spark integrates seamlessly with Hadoop, running on top of Hadoop YARN within Terrascope. This integration enables us to utilize Spark’s potent batch and stream processing features to tackle various big data challenges.
YARN
YARN (Yet Another Resource Negotiator) plays a vital role in our cluster management by overseeing resource allocation and task scheduling. Similar to an operating system, YARN manages our computing cluster’s storage (via HDFS) and processing resources. This ensures that computational tasks are allocated and scheduled optimally, maintaining the efficiency and performance of our platform. By leveraging YARN, we can dynamically manage resources, improving the overall utilisation and throughput of our data processing workflows.
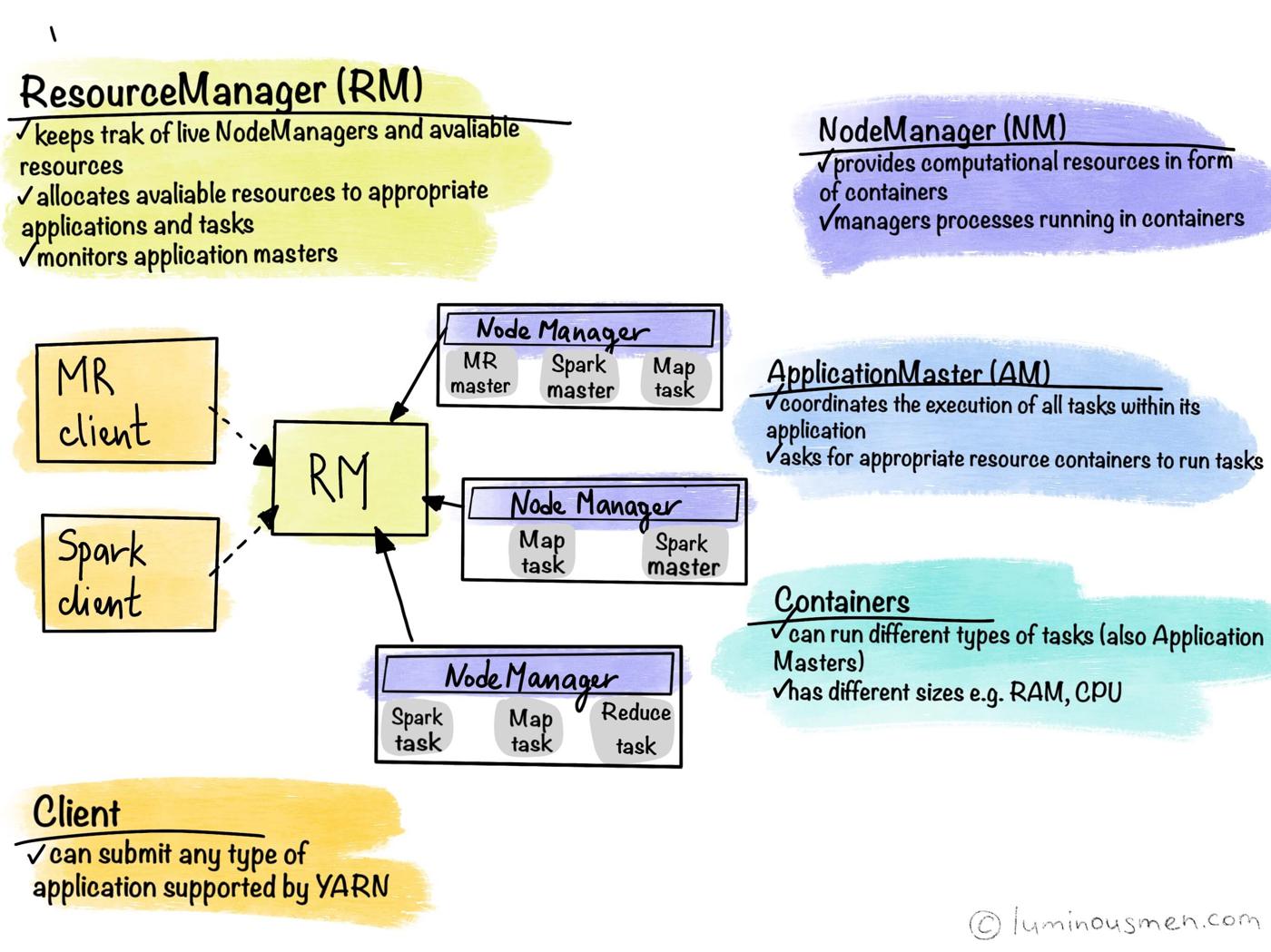
More details on the resource management by YARN can be found here.
Cluster overview
Terrascope currently operates two Hadoop clusters:
- an old (legacy) Hadoop cluster, which many existing jobs still use and which is the default target for the
userVMconfiguration; - a new Hadoop cluster (backed by the
*.hadoop.rscluster.vito.beendpoints) that provides the upgraded environment described on this page.
While the old cluster remains available during a transition period, it is strongly recommended to start using the new cluster for all new workloads and to migrate existing jobs where feasible. The old cluster is planned to be phased out by the end of June 2026.
Connecting to the New Hadoop Cluster
Terrascope has migrated to a new, upgraded Hadoop cluster. By default, the userVM is configured to interact with the old cluster. To use the new cluster, you must set the following environment variables before running any commands.
For hdfs and yarn Commands
If you need to interact directly with HDFS or YARN on the new cluster, run these commands first:
export HADOOP_HOME=/usr/local/hadoop/
export HADOOP_CONF_DIR=/usr/local/hadoop/etc/hadoop/
export PATH=/usr/local/hadoop/bin/:$PATHFor spark-submit Commands
To ensure your Spark jobs are submitted to the new cluster, you must set these variables in addition to the above. The new cluster supports both Spark 3.5.0 and Spark 4.0.1.
For Spark 3.5.0:
On the old cluster, Spark uses the configuration directory conf (e.g. /opt/spark/conf). On the new cluster, Spark 3.5.0 uses a separate directory: conf2. Set:
export SPARK_HOME=/opt/spark3_5_0/
export SPARK_CONF_DIR=/opt/spark3_5_0/conf2/For Spark 4.0.1:
Spark 4.0.1 uses a single configuration directory and requires Java 17. The new cluster has Java 8, 11, and 17 installed, so you must set JAVA_HOME explicitly to Java 17 when using Spark 4.0.1:
export SPARK_HOME=/opt/spark4_0_1/
export SPARK_CONF_DIR=/opt/spark4_0_1/conf/
export JAVA_HOME=/usr/lib/jvm/jre-17The Java 17 path may differ on your system (e.g. /usr/lib/jvm/java-17-openjdk or /usr/lib/jvm/jre-17). Use the path that matches your installation.
To make this easier, helper scripts are available in the hadoop-spark-samples repository. If you have cloned this repository, you can source these scripts:
source scripts/source_new_cluster # For Spark 3.5.0
# or
source scripts/source_spark4.sh # For Spark 4.0.1Note: The source_spark4.sh script automatically configures JAVA_HOME to Java 17, which is required for Spark 4.0.1. Because the new cluster has Java 8, 11, and 17 available, setting JAVA_HOME explicitly ensures the correct version is used. Tips:
- If
spark-submitis not found when you run it manually, use${SPARK_HOME}/bin/spark-submit(the source scripts setSPARK_HOME). - In the hadoop-spark-samples repository, many submission scripts choose the Spark version via the
SPARK_VERSIONenvironment variable. SetSPARK_VERSION=4.0.1orSPARK_VERSION=4before running such a script to use Spark 4.0.1. - To verify that Java 17 is available:
ls -d /usr/lib/jvm/java-17-openjdk* 2>/dev/nullor runjava -versionafter settingJAVA_HOME.
Submission methods
Docker is the preferred method for production workloads. Python virtual environments and Conda are also supported. You can submit Spark jobs to the new cluster in three main ways:
- Docker containers (preferred) — Run the driver and executors inside Docker images for full control over Spark and Python versions. See Using Docker on Hadoop for setup and configuration.
- Python virtual environment (archives) — Bundle your Python environment as an archive, upload it to HDFS once, and reference it in
spark-submitwith--archives. See Starting your first Spark job for a minimal example. - Conda — Use Conda to create and pack an environment, then ship it to the cluster (similar to venv). Suited for complex scientific dependencies. Examples are in the hadoop-spark-samples repository.
Sample code and advanced examples (venv, conda, Docker) are available in the hadoop-spark-samples repository.
Additional Resources
Various guides and best practices are available for users to start or learn more about setting up a Spark job, managing resources, and accessing logs. These resources cover topics such as: These resources cover various topics, including:
Start a Spark Job:
To speed up processing in Terrascope, it is recommended that tasks be distributed using the Apache Spark framework. The new cluster runs Spark versions 3.5.0 and 4.0.1. Spark is pre-installed on the Virtual Machine, allowing
spark-submitto run from the command line. Theyarn-clustermode (orclusterdeploy mode) must be used for Hadoop cluster jobs, and authentication with Kerberos is required by runningkiniton the command line. Commands likeklistandkdestroyhelp manage Kerberos authentication status. Make sure to set the appropriate environment variables (as described above) to connect to the new cluster. A Python Spark example to help users get started.Manage Spark resources:
Optimizing Spark resource management is crucial for efficient data processing. This guide provides insights into configuring Spark resources effectively, ensuring optimal performance and resource utilization. For an in-depth understanding of Spark resource management, refer to the Spark Resource Management guide.
Advanced Kerberos:
To use Hadoop services, including Spark, YARN, and HDFS, users must have a valid Ticket Granting Ticket (TGT). This page summarises insights on Kerberos.
Access Spark Logs:
Accessing Spark logs is essential for monitoring and troubleshooting Spark jobs. Refer to the Accessing Spark Logs section for detailed instructions on accessing Spark logs.
Using Docker on Hadoop:
For users interested in running Docker on Hadoop, this page provides detailed instructions on setting up Docker on Hadoop. This could be useful when the user wants to use a spark or Python version that isn’t available on the cluster.
Manage permissions and ownership:
Managing file permissions and ownership is crucial for ensuring data security and integrity. Refer to the Managing Spark file permission and ownership page for insights on managing Spark file permissions and ownership.
Spark best practices:
Additionally, to have a better understanding of Spark best practices, it is recommended to refer to the Spark best practices guide. This guide provides insights into optimizing Spark workflows and enhancing data processing efficiency.